Tracking The OSINT Hunter
Gathering open-source intelligence, when done properly, should be an anonymous affair, it simply will not do to leave your digital footprints behind.


Gathering open-source intelligence, when done properly, should be an anonymous affair, it simply will not do to leave digital footprints and breadcrumbs behind which could later be used to track you. In this article we cover the different online tracking techniques which could be used to track you and suggest countermeasures to mitigate against them when conducting OSINT gathering operations.
There are different actors interested in tracking internet users, each have their own motivations. For example, advertisers are increasingly monitoring people’s online behavior to target them with customized advertisements, this type of tracking is referred as Online Behavioral Advertising (OBA) and is partly what has fueled the explosive growth of social networking sites which try to track your every move.
Web analytics services (e.g. Google Analytics) also track online users to collect website usage statistics, intelligence agencies on the other hand track online users on a mass scale to analyze global digital information and to predict future political, military and economic changes. Law enforcement and intelligence services agencies use public information available online to gain intelligence about their targets. The information acquired from public sources is known as Open Source Intelligence (OSINT) and it refers to all the information that is publicly available. OSINT sources are distinguished from other forms of intelligence because they must be legally accessible by the public without breaching any copyright or privacy laws.
Obviously, being anonymous is an important prerequisite for any intelligence gathering activity, for example, consider an investigator conducting an OSINT operation against drug dealers in South America. What if the people the investigator is investigating discovers his search? What if they could learn the source of the search, the organization behind it and the searcher’s location or identity?
Revealing the searcher’s identity when conducting OSINT searches can have dangerous, and even legal, consequences in many instances. The same issue applies in the business world, consider a corporation conducting a search to enter a new market, what if other competitors working in the same field discover this act
Protecting the privacy of your operations is the key to OSINT success.
This article is divided into two sections, in the first we will explore the concept of “online tracking” and introduce the different technical methods used to track people online and suggest countermeasures against it. Many junior OSINT practitioner’s believe that using a VPN service is enough to conceal their online traces online and this is completely wrong, using a VPN will only conceal your IP address leaving your other technical footprints obvious and apparent for any trackers who follow you.
The concept of full online anonymity is extremely difficult to achieve, becoming completely anonymous online requires using a set of tools and tactics to conceal any trace that can reveal your identity or even the type of hardware and connection you are using to access the internet, and this requires some serious technical skill. Cases related to national security or foreign espionage require this level of anonymity and are usually conducted by security agencies who know well how to conceal their gathering activities. But for the purpose of conducting regular OSINT gathering activities, you need to become anonymous up to a suitable level so that the subject cannot discover that we are trying to find information about them.
In the second part, and after knowing about the various online tracing techniques and how to counter them using a plethora of tools and tactics, we will propose a solution that allows online surfers to isolate their browsing activities from their local networks and infrastructure using a virtual machine for OSINT operations.
What is Online Tracking?
Online tracking can be defined as the process of recording the internet browsing history, and sometimes the online behavior, of internet users across different websites. In order to link the browsing history to the subject user, an identifier will be used to distinguish each online user as an individual which can be tracked.
This identifier is similar to a person’s fingerprint as it can distinguish a particular user machine among millions of connected users. The following section will demonstrate how online tracking works technically.
Online Tracking Techniques
Online tracking typically leverages one, or more, of the following methods:
IP Address Tracking
A computing device cannot access the internet without having an Internet Protocol (IP) address, an IP address is a unique identifier that identifies any internet capable device when connecting to the IP network (hence, the internet). No two devices can own the same IP address on the same IP network, this what makes an IP address the first choice for online trackers when tracking users online.When connecting to the Internet, you either use the same IP address each time (static IP) or use a different number each time (known as dynamic IP).
A static IP address is an address assigned by your Internet service provider (ISP) and does not change over time; Static addresses are usually used by businesses, public organizations, and IT companies that offer IT services to individuals and the private sector. By contrast, a dynamic IP address is assigned dynamically by your ISP whenever you connect to the Internet. It uses a protocol called Dynamic Host Configuration Protocol (DHCP) to assign you a new IP address every time your computing device or router gets rebooted. Some ISPs may allocate the same IP number previously assigned to you many times, but this is not a rule of thumb.
Please note, an IP address can be spoofed (concealed) when going online using different techniques such as VPN and anonymity networks like the TOR network. A user can also sit behind a NAT router where a single public IP address is shared for all computing devices belongs to the same network. For these reasons, we cannot consider an IP address alone enough to distinguish an individual online user on today’s internet. However, it still remains the first choice to track people online.
To know how to choose a VPN provider, check my detailed guide here on Secjuice.
Cookie Tracking
Cookies are the most common technique to track online users, a cookie is a small text file created when a user visits a particular website, the standard information contained within it includes a unique ID that distinguishes client device, an expiration date and the cookie website name. A cookie is used to distinguish a client device when returns back again to the same website. Websites use cookies mainly for two purposes: storing login credentials and tracking user online behavior.
A basic cookie file (also known as an HTTP cookie) is what the majority of people mean when talking about web cookies. An HTTP cookie is a simple text file used for tracking user visits to the web site that deployed it. HTTP cookies without expiration date are automatically deleted when the browser is closed. However, expiration dates can be many years into the future. There are mainly two types of cookies in terms of their life span: Session and Persistence cookies.
A Session Cookie is stored in temporary memory and is erased when the user closes the browser, this type of cookies does not have an expiration date and it does not store any information about the user client device. It is usually used to maintain shopping cart contents in e-commerce websites.
A Persistent Cookie (like Flash and evercookie cookies) raise serious privacy concerns. Half of a cookie’s contents are first-party and belong to the site you are visiting, and half are third-party and belong to partners, services, or advertisers working with the site. Third-party cookies are used to track activity (across multiple web sites) and recognize frequent and returning visitors, to optimize advertising, or to improve the user experience by tailoring the content or offers based on that cookie’s history. The main two types of persistent cookies are Flash and Evercookies.1.
Flash Cookies are more persistent than traditional cookie files that have an expiration date and are stored in a specific folder on the client hard drive. Deleting web browser cookies folder will not erase this type of cookie. Flash cookie is used to store users browsing history across multiple websites and can be sued to re-instantiate HTTP cookies deleted by the user. To access all Flash cookies stored in your machine (Under Windows) go to the Control Panel ➤ Flash Player and select the option “Block all sites from storing information on this computer” (See Figure 1).
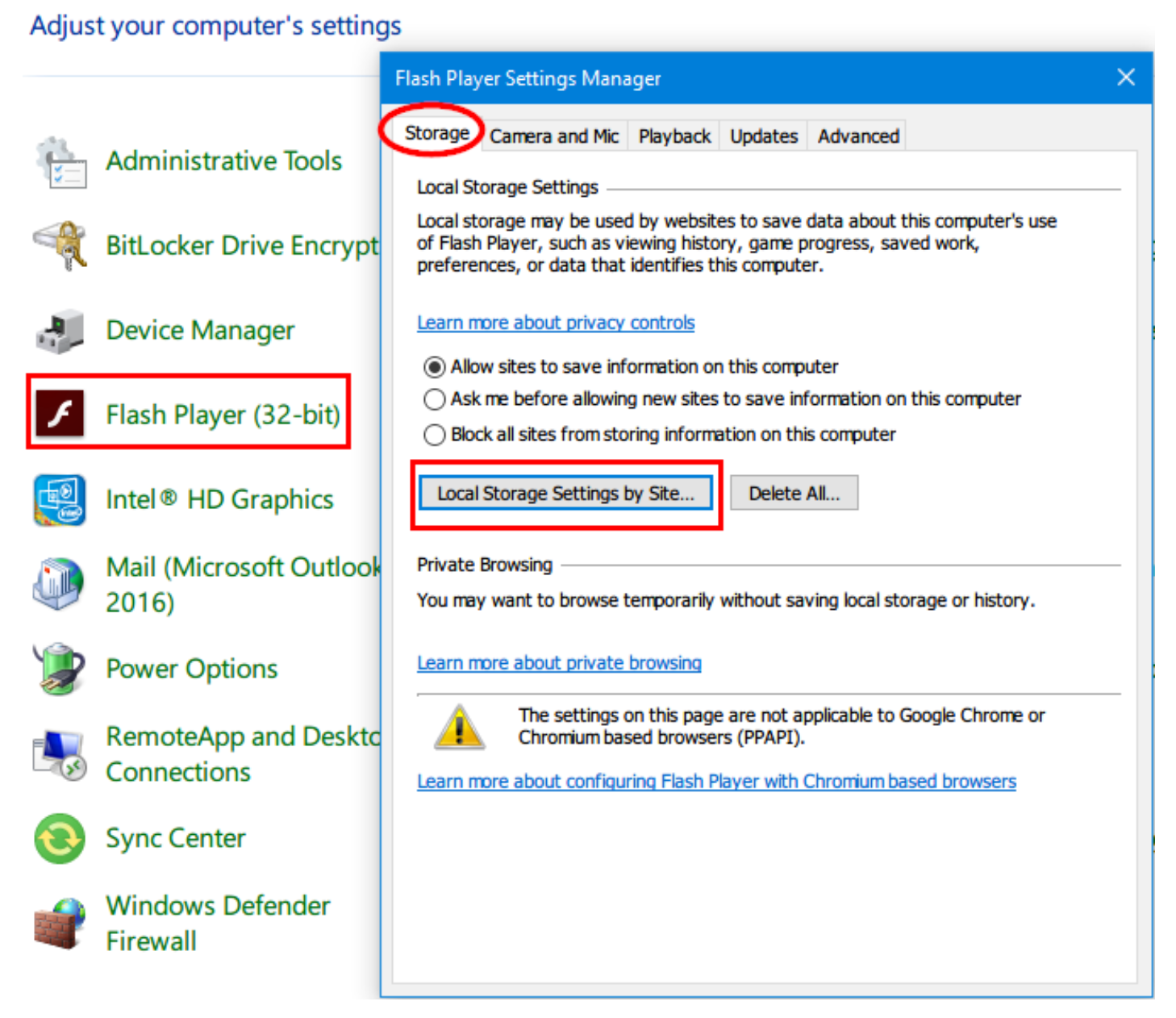
We can also use a tool to display a list of Flash cookies that exist on our system and delete them, FlashCookiesView is a portable tool created by NirSoft to this end.
Evercookies Cookies: According to developer Samy Kamkar, an evercookie is a JavaScript-based cookie that can survive even after the user deletes HTTP and Flash cookies from his or her machine. It accomplishes its persistence by storing its data in several locations on a client browser/machine (for example, in an HTTP cookie, Flash cookie, HTML5 local storage, web history, Silverlight). If one of these locations is deleted, for example, by the user, the evercookie will detect this and regenerate itself. Thankfully, modern web browsers are now able to block or detect evercookies.
ETag Tracking
ETags are another way of tracking the user without using cookies (both HTTP and Flash), JavaScript, HTML storage, or IP addresses. The ETag, or entity tag, is part of a Hypertext Transfer Protocol (HTTP) mechanism that provides web cache validation and is intended to control how long a particular file is cached on the client side.
ETags help a web browser to avoid loading the same web resources twice, such as when a user visits a web site that plays music in the background that changes according to a user’s local time. On the first visit, the web server will send an ETag along with the audio file to the client browser, which will download the audio file and cache it. When the user visits the same web site again, the web server will inform the client browser that the audio file has not changed. As a result, the browser will use the local copy in the cache, saving bandwidth and speeding load time.
If the ETag is different, then the client browser downloads the new version of the audio file. ETags can be exploited to track users in a similar way to persistent cookies, and a tracking server can continually send ETags to a client browser, even though the contents do not change on the server. By doing this, a tracking server can maintain a session with the client machine that persists indefinitely. To get rid of ETags, you must clear the browser cache content.
Digital Fingerprinting
A browser fingerprint is the set of technical information about a user’s system and browser that can distinguish his or her machine online. This information includes the following: browser type, operating system (OS) version, add-on installed, user agent, fonts installed, language settings, time zone, screen size, and color depth, among other things. Fingerprinting allows trackers to distinguish a user’s machine even though cookies and JavaScript are disabled. A fingerprinting-specific browser is stateless and transparent to the user and machine.
The information collected from a digital fingerprint may seem generic and not enough to identify an individual machine online among millions of connected devices; however, if this information is combined, you can draw a comprehensive unique picture about each user machine, and later, this information can be linked to a real identity if combined with other Personally identifiable information (PII).
This should effectively allow different outside parties to easily profile people without using traditional tracking techniques such as computer IP addresses and cookies.The Electronic Frontier Foundation (EFF) published an excellent study in May 2010, detailing some of the various methods of fingerprinting a browser.
The result concludes that the majority of Internet users can be profiled and tracked online using only minor technical information from their browsers. Although the study was conducted in 2010, its results are still valid now because of the transparent way fingerprinting occurs in digital devices. There are two main types of device fingerprinting: script-based techniques and canvas.
Script-Based Fingerprinting
Script Fingerprinting works by loading a script (generally JavaScript) into the user’s browser. Once the script is loaded successfully, it will execute to extract a wide array of technical information about the current browser and system configuration. The information extracted includes user agent, add-on/extensions installed, fonts installed, screen resolution, time zone, operating system type and version, CPU and GPU type, and many other details about the targeted system.
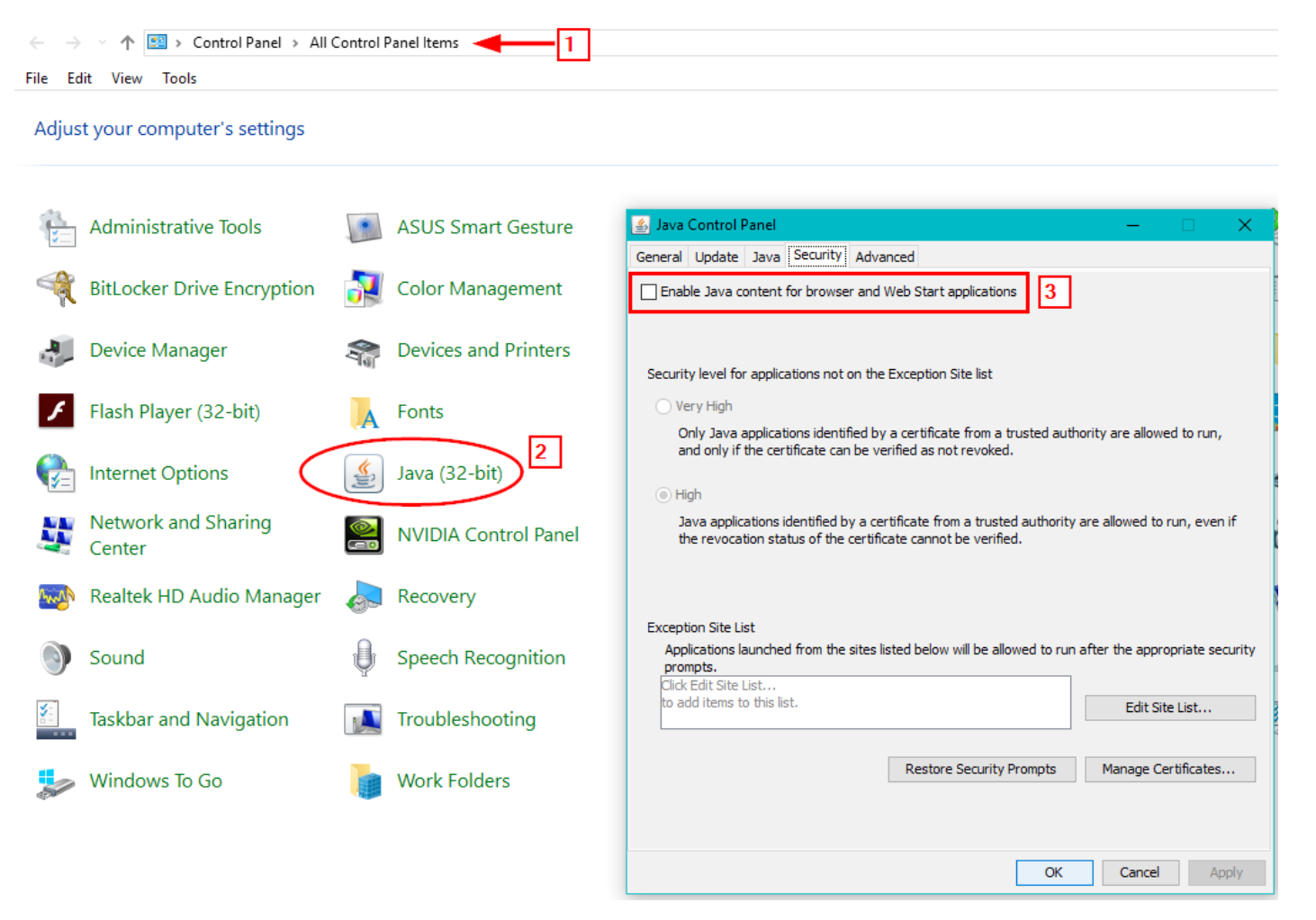
A hash is then made based on the information the script has collected. That hash can help identify and track your device as an IP address would. Trackers use Flash, Silverlight, or a Java applet to perform the fingerprinting instead of JavaScript; they will all return the same result. The main defense against this technique is to disable JavaScript in your browser. However, this approach is not practical and may result in breaking a large number of web sites (the majority of web design frameworks are now based on JavaScript to deliver functionality). Disabling Java (see Figure 2) will not cause problems like disabling JavaScript.
Canvas Fingerprinting
Canvas is an HTML5 element originally developed by Apple; it is used to draw graphics (lines, shapes, text, images) and animation (e.g., games and banner ads) on web pages using a JavaScript API. Apart from web development, canvas features can be exploited by advertisers to fingerprint browsers and profile internet users.
Canvas fingerprinting is a new method for tracking users’ online activities. It simply works by drawing an invisible image on the user’s client browser. This image will be different for each user, and once drawn on the client browser, it will collect different technical information about the user’s browser and machine. A hash is then made based on the information the canvas has collected. This hash will be consistent across all the web sites the user visits (the hash is generated from the canvas data); this will effectively record a user’s browsing history. Although the collected information from canvas fingerprinting cannot be used alone to identify users, this fingerprint can be combined with other sources to identify you completely.
Countermeasures for Browser Fingerprinting
Fingerprinting is currently considered to be the greatest risk that faces users when surfing online. To understand how we can stop this invasion to our privacy, let’s begin by seeing what your current digital fingerprint shows to the public. The following are popular web sites that offer such services for free.
- Panopticlick (https://panopticlick.eff.org)
- DeviceInfo (https://www.deviceinfo.me)
- Browserleaks (https://browserleaks.com)
- AmIUnique (https://amiunique.org)
Configure Your Web Browser For Better Security
Major web browsers can be configured to become more privacy-friendly (e.g. delete browsing history and cookies automatically), each web browser has its own set of privacy configurations to achieve this goal. A user can also use private browsing mode to erase browsing history, saved passwords and cookies automatically. In Firefox it called “Private Browsing” and can be accessed by pressing the following button combination(Ctrl + Shift + A) while in Chrome it called “Incognito mode”.
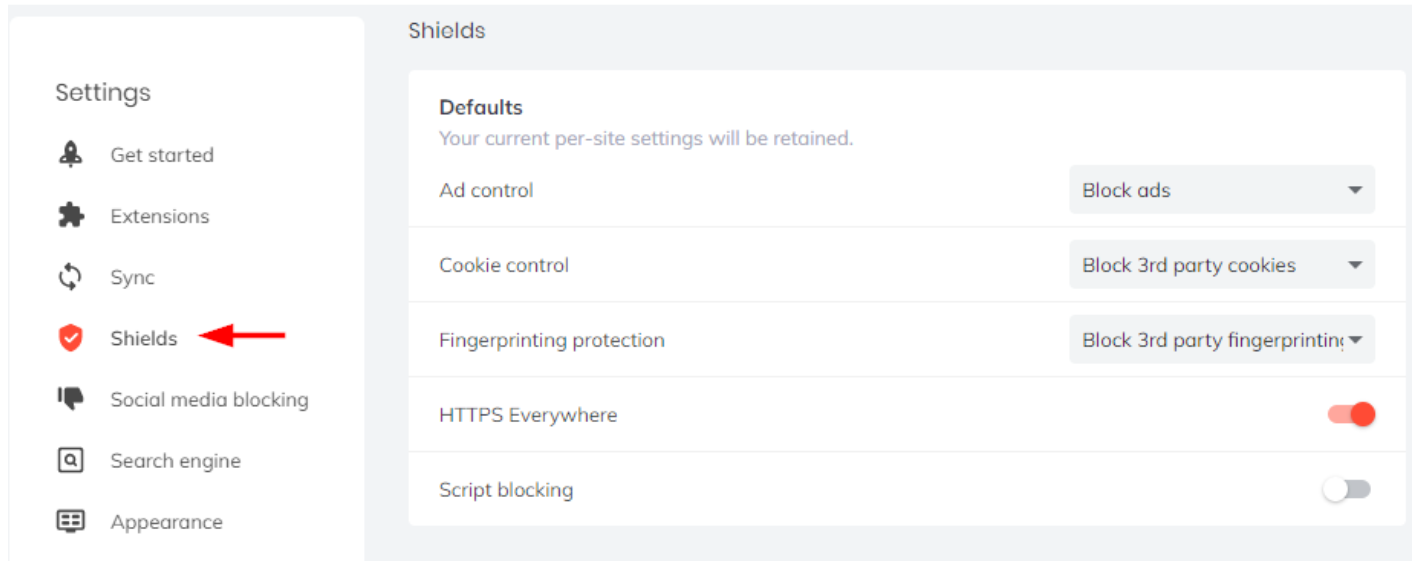
Brave browser is a privacy-focused web browser based on the Chromium project and which accepts Chrome extensions. Brave blocks different online tracking mechanisms by default, you can enable fingerprinting protection by going to Settings and then clicking on Shields (see Figure 3).
Browser Extensions for Privacy
There are many privacy add-ons available to stop -or mislead- online trackersfrom following you online, the following are the most reputable one:
- Privacy Badger - block invisible trackers (https://www.eff.org/privacybadger)
- Disconnect – Block invisible websites (https://addons.mozilla.org/en-US/firefox/addon/disconnect)
- uBlock Origin – another efficient blocker (https://addons.mozilla.org/en-US/firefox/addon/ublock-origin)
- HTTPS Everywhere - encrypts your communications with many major websites, making your browsing more secure (https://www.eff.org/HTTPS-EVERYWHERE)
- CanvasBlocker - Alters some JS APIs to prevent fingerprinting (https://addons.mozilla.org/en-US/firefox/addon/canvasblocker)
- Cookie AutoDelete – Automatically delete cookies upon tab closes (https://addons.mozilla.org/en-US/firefox/addon/cookie-autodelete)
- Decentraleyes - Block Content Delivery Networks (https://decentraleyes.org)
- uMatrix - A point-and-click matrix-based firewall, with many privacy-enhancing tools (https://addons.mozilla.org/en-US/firefox/addon/umatrix)
- User-Agent Switcher - switch between popular user-agent strings (https://addons.mozilla.org/en-US/firefox/addon/user-agent-switcher-revived)
Search Engine Tracking
Typical search engines such as Google, Yahoo! and Bing are known to track their user's searches to target them with tailored ads and to customize returned search results. For example, the majority of Google search engine users own a Gmail account (The Google free email service), when a user conducts online searches using Google while logged on to a Gmail account, the user online activity’s will get recorded and linked to his/her Gmail account (Which tend to be a user real identity).
Even though a user has not logged to Gmail account, Google can still link a user browsing history to his/her real identity using any of the previous tracking techniques already mentioned. When searching for OSINT sources, it is advisable to use a privacy-oriented search engine that does not record your search history or customize returned results according to criteria settled by the search provider.
There are many anonymous search engines that do not track their user’s activities, you can find a list of them at https://osint.link/#privacy.
Social Networking Tracking
Social networking sites such as Facebook and Twitter can track online users across different websites (they can actually track most internet users browsing history) even though those users are not currently logged on to their associated accounts!
For example, as we all see when browsing online, most websites have a Facebook “Like” and “Share” buttons that facilitate sharing content on a user’s Facebook news feed. Till now, this action is quite normal and useful, however, what you should know is that whenever you visit a webpage that has a Facebook “Like” or “Share” button, Facebook will record this visit even though you did not click the button! Facebook tracking will not stop at this point, as they can track non-Facebook users across different websites using the hidden code embedded inside their “Like” and “Share” buttons without the users knowledge and they do!
Twitter “Follow” button, also play the same role in tracking online users just like Facebook “Like” and “Share” buttons.
Evading Online Tracking
As we already saw, a user can be tracked online using different techniques, and countering these techniques require different tools and tactics to be implemented correctly. To prevent online tracking, a user must perform three main steps:
- Conceal his/her machine IP address using a reliable VPN service.
- Delete -or reject- cookies and web browser cache after closing the browser.
- Prevent digital fingerprinting techniques from profiling hi/her machine.
As I mentioned earlier this requires serious technical skills. Fighting against tracking and fingerprinting is difficult, and there isn't a 100 percent guaranteed technical solution to the problem. Even after configuring your web browser for better privacy and installing many add-ons, skilled adversaries can still recognize your digital fingerprint to a large extent.
The best technical solution to fight against browser fingerprinting is to make your browser look like most browsers’ fingerprint! To achieve this, it is advisable to use a freshly installed copy web browser configured manually with privacy-enhanced settings without installing any add-ons. This browser should run from a virtual machine (e.g. Virtual Box https://www.virtualbox.org) that also freshly installed.
By using this technique, your browser will look like most running browsers and thus effectively conceal your true digital footprint. Of course, you still need to use a VPN to encrypt your connection and conceal your true IP address.
About The Author: Nihad Hassan (@DarknessGate) is the author of a number of books on digital forensics, open source intelligence and digital security. You can learn more about the best methods to assure your digital privacy online, in his recent book Digital Privacy and Security Using Windows published by Apress. Other books related to OSINT and Digital Forensics from the same author can be found here.
